
Every time a major LLM provider releases a new model, people tend to think about how LLMs can replace humans in certain tasks. And this take is true – better, larger, and potentially faster models can do much more than their predecessors.
However, many tasks are just too specific or require a lot of domain knowledge, and off-the-shelf generalist LLMs are just not good enough out of the box.
There are many techniques to improve the task alignment of LLMs, ranging from propmt engineering to fine-tuning, to training-time human feedback. The general idea is that, just like in traditional ML, we need human feedback in a certain shape – most often a well curated dataset.
This is where labeling comes into play. In a very broad sense, labeling is the process wherein a human attaches a key-value pair to a (possibly generated) data point. The main purpose of labeling is to distinguish and filter out different classes of data and ultimately to collect a "good" dataset that can be used to train, fine-tune, or prompt-tune a model.
Regardless of what you are building – be it your production agent or an LLM-as-a-judge evaluator – it is useless, if not harmful, without human alignment.
From our experience, teams benefit the most from labeling when:
- Multiple people are involved in the labeling process, potentially with overlapping datasets
- Domain experts are involved in the labeling process
- In case of LLM-as-a-judge, manual labeling is done with the same criteria as the LLM-as-a-judge
The biggest challenge is that domain experts are not necessarily familiar with the concepts of spans, telemetry, and JSON. This makes it even harder to accommodate for both technical and non-technical team members in the labeling process.
To address this, we've added a new feature to Laminar – labeling queues.
Labeling Queues
Labeling queues are a way to label data in Laminar. They are designed to be simplistic views where a user can see one data point at a time and can attach labels to it.
Data points in the queues are added first-in-first-out (FIFO) basis, but the person labeling can move back and forth in the queue. This decision was deliberate, so labelers can't easily see the entire queue, but can compare data points.
On Laminar, there are currently two ways to add data to the labeling queues:
- Exporting data from spans view
- When running evaluations, sending the same data points for human labeling
Getting started is simple. We first need to create a new labeling queue. Then, we choose a span that we want to label and add it to that queue.
We can then see the span inside the labeling queue and attach labels to it.
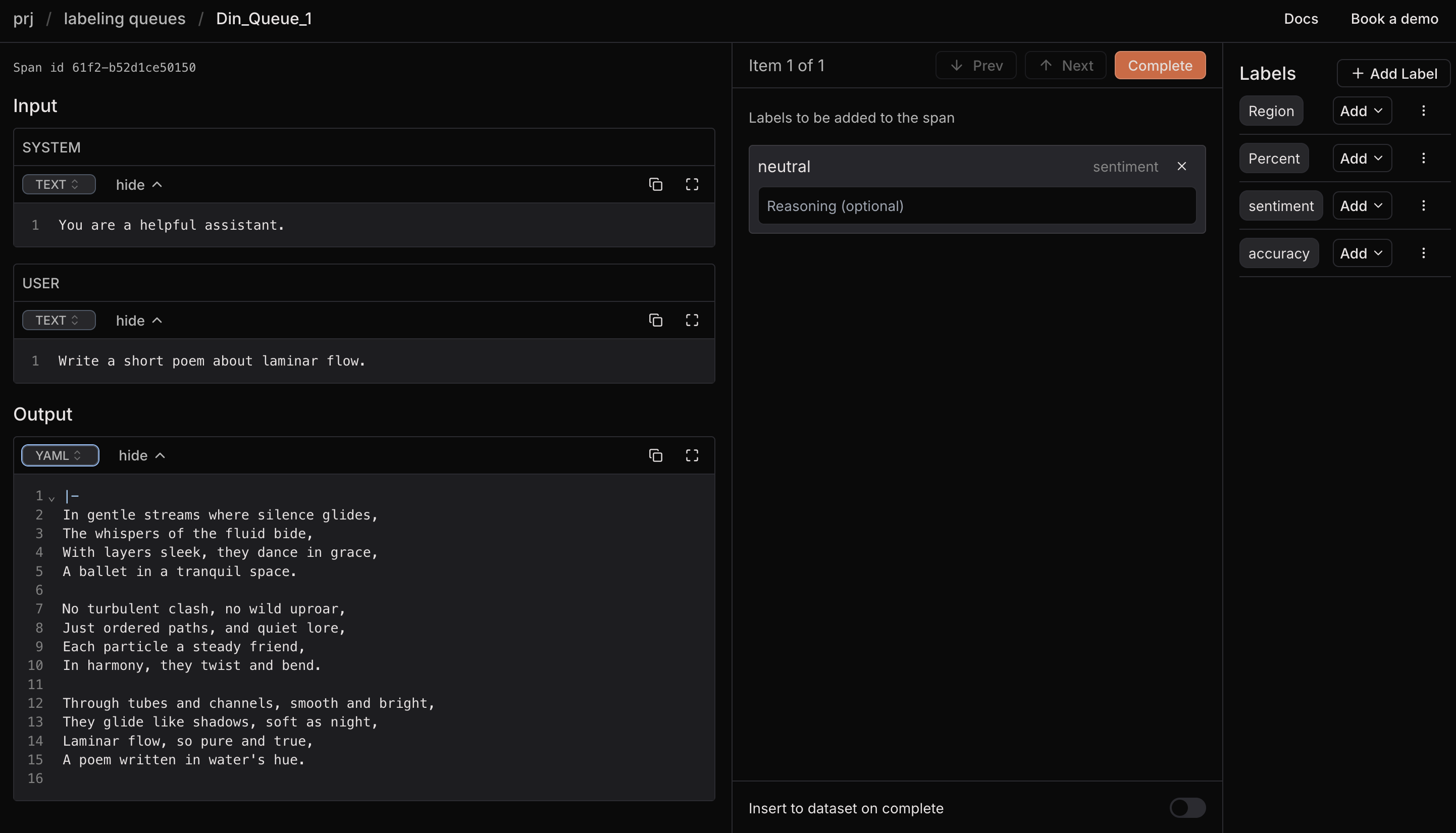
As you can see, we can add labels and add reasoning/comments to each label value.
Human labelers
Another mode to add data to the labeling queues is to run evaluations registering a human evaluator. This is useful when you want to run an LLM-as-a-judge evaluation and ask humans to label the same data points – and then compare the results to track the alignment of the LLM-as-a-judge.
To register a human evaluator, simply add an array of HumanEvaluator objects to the evaluation configuration.
TypeScript:
import { evaluate, HumanEvaluator } from '@lmnr-ai/lmnr';
evaluate({
data: evaluationData,
executor: async (data) => await getCapital(data),
evaluators: { checkCapitalCorrectness: evaluator },
projectApiKey: process.env.LMNR_PROJECT_API_KEY,
humanEvaluators: [
HumanEvaluator("my_queue"),
HumanEvaluator("my_other_queue"),
],
})
Python:
from lmnr import evaluate, HumanEvaluator
import os
evaluate(
data=data,
executor=get_capital,
evaluators={'check_capital_correctness': evaluator},
project_api_key=os.environ["LMNR_PROJECT_API_KEY"],
human_evaluators=[
HumanEvaluator(queue_name="my_queue"),
HumanEvaluator(queue_name="my_other_queue")
],
)
When human labelers attach labels to the corresponding data points in the queue, the numeric values are added back to the same evaluation and can be compared to the evaluator's numeric values side by side.
Read more in our docs.
Actions
Labeling queues also have various actions. Numeric labels that go back to the evaluation is one example. We start with an ability to add labeled data points to Laminar datasets of your choice.
This is the simple basis, but we have plans to add more actions in the future to facilitate numerous labeling workflows and empower the true data flywheel.
The future
Labeling queues are a very new concept, and we are excited to see how they can be used in practice. If you have interesting use cases in mind and ideas on how to improve the feature, please let us know! We are always open to feedback and suggestions on Discord.