
It is no secret that evaluations are a critical part of any system with any amount of non-deterministic behavior, and LLMs are not an exception.
Almost every single LLM or AI dev tool has evaluations today, and many people even consider evaluations a core part of LLM observability. Many platforms started with observability and added evals later, some did the opposite. Evaluations can take many forms, from simple deterministic checks to LLM-as-a-judge.
In this blog post, we briefly talk about evaluations in general and what we believe are the best practices, and then we dive into how we to use evaluations on Laminar.
What is an evaluation?
From the meaning of the word itself, evaluation is a process of assessing the value or quality of something. In the context of LLMs, it is a process of assessing the output of a model given the prompt and an input.
We like to think of evaluations as unit tests for LLMs. The main difference here is that the tests are not deterministic, and the same input can produce different outputs on different runs.
Thus, very simple assertions like output == expected_output are not enough, and so the results of each evaluation can be broader than just pass or fail.
Best practices
Here are some of the things we believe work best for evaluations.
Define evaluations in code
LLM-as-a-judge is powerful, but code gives you much more flexibility. And guess what? You can call LLM-as-a-judge in code, so code evaluations are, in a sense, a superset of LLM-as-a-judge.
Evaluate each step separately
It is very tempting to evaluate the entire execution of a complex agent, especially if you want to make sure the agent does not go off-track. While we think there is value in doing so, we think that evaluating each step separately is even more important.
The main problem with evaluating the entire execution is that it is hard to tell whether the failure is due to a specific step and at what point it happened. There are just too many moving parts.
On the other hand, if we evaluate each step separately, we can pinpoint exactly where the failure is coming from.
Evaluation dataset should be representative
Ideally, use real production traces as evaluation datasets. If this is not available, make sure that the dataset is as similar to production as possible. It is very easy to miss important nuances when evaluating on a synthetic dataset, especially if it is created without the production examples in mind.
Adopt evals as early as possible
Start doing evaluations as soon as you can. Track the progress of your prompts' performance over time and as you make changes. You will learn a lot about your system and the best ways to design it.
Evaluations on Laminar
We built evaluations on Laminar with all of the above in mind. We stick to the following principles:
- Evaluations are defined in code.
- An executor (forward run) must be actual production code.
- Evaluators are just functions that take an executor's output and target output, and return a result.
- All of the above must be defined by the user.
- Evaluations are as little intervention as possible, so you can run them manually or in your CI/CD pipeline.
Laminar evaluations are a tool for you to analyze the quality of your system rigorously. We implemented them in such a way that they don't get in the way of your development process, and give you the flexibility to use them in any way you want.
Simple evaluation
Suppose you have a step in your agent that decides which tool to call based on the input. It could be a simple call to an LLM API with tool definitions, for example:
TypeScript
const tools = [
{
type: "function",
function: {
name: "my_tool_1",
parameters: [
// ...
],
},
}
// ...
];
async function decideTool(input: string) {
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [{ role: "user", content: input }],
tools,
});
return response.choices[0].message.tool_calls;
}
Python
tools = [
{
type: "function",
function: {
name: "my_tool_1",
parameters: [
# ...
],
},
},
# ...
]
async def decide_tool(input: str) -> list[ToolCall]:
response = await openai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": input}],
tools=tools,
)
return response.choices[0].message.tool_calls
Let's say we have collected a dataset of inputs and expected outputs for this function. We can define an evaluation for it as follows:
TypeScript
// my-eval.ts
import { evaluate } from '@lmnr-ai/lmnr';
import { decideTool } from './my-module';
const data = [
{ data: { input: "input 1" }, target: "tool1" },
{ data: { input: "input 2" }, target: "tool2" },
// ...
];
evaluate({
data,
executor: decideTool,
evaluators: {
exactTool: (output, target) => output.name === target,
},
config: {
projectApiKey: "...", // Your Lamianr project API key
}
});
And then simply run npx lmnr eval my-eval.ts.
Python
# my-eval.py
from lmnr import evaluate
from my_module import decide_tool
data = [
{"data": {"input": "input 1"}, "target": "tool1"},
# ...
]
evaluate(
data,
executor=decide_tool,
evaluators={
"exact_tool": lambda output, target: output.name == target,
},
project_api_key="...",
)
And then simply run lmnr eval my-eval.py.
You will see the results in your Laminar project dashboard.
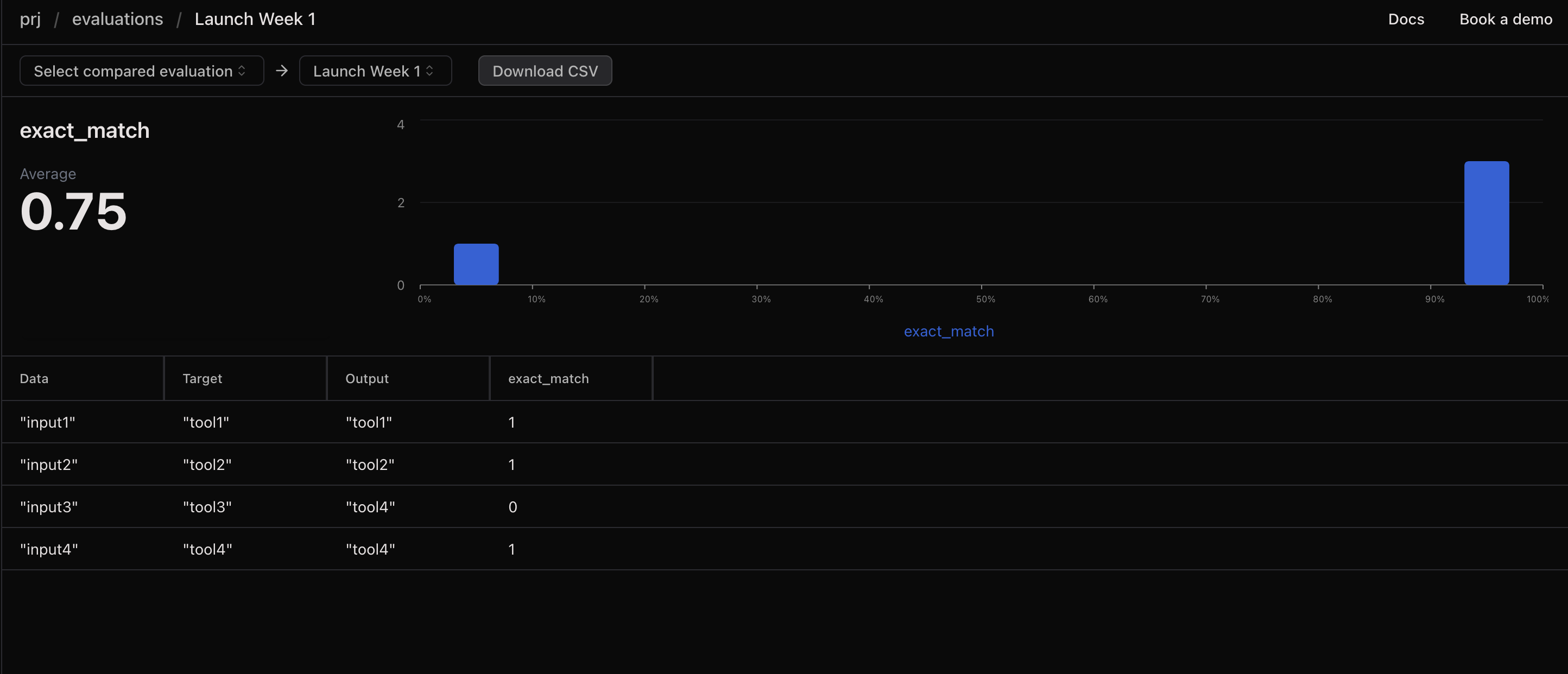
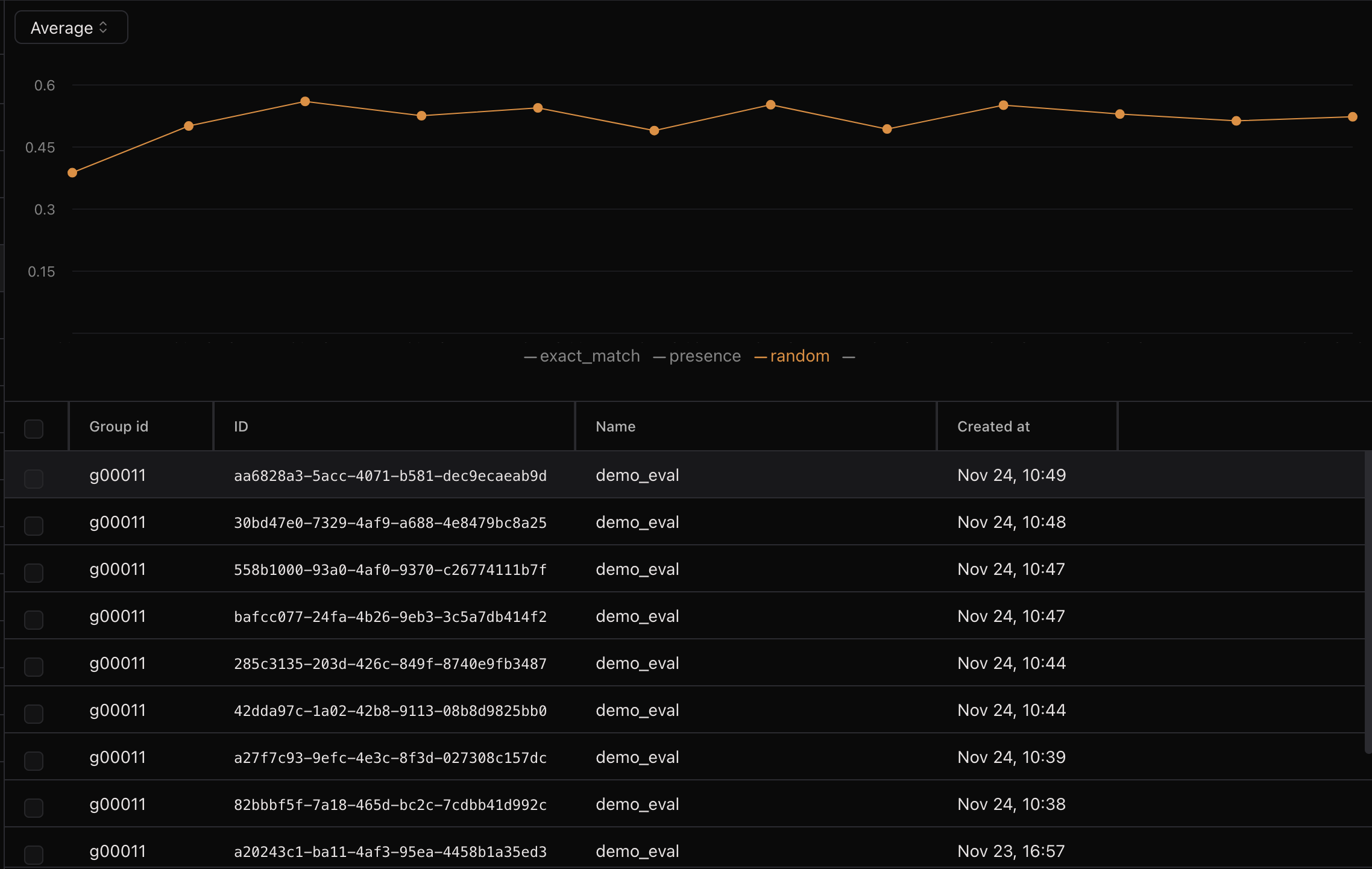
And if you repeat this evaluation multiple times, you will see the progression of the evaluation scores over time.
Many more features
In addition to the visualization, Laminar evaluations allow you to:
- See the full trace of the entire run, including all LLM calls,
- Compare scores across runs,
- Register human labelers to assign scores alongside these programmatic evaluations,
- Use datasets hosted on Laminar to run evaluations.
Read more in the docs.